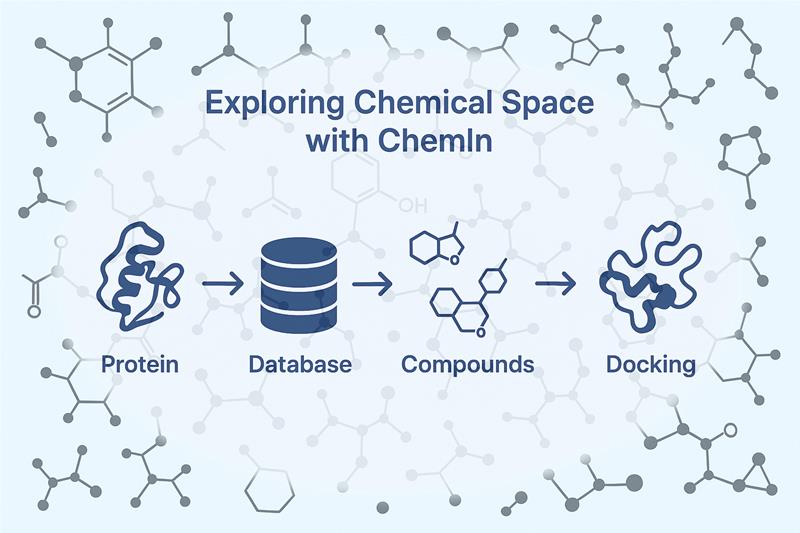
Exploring Chemical Space with ChemIn: The Cheminformatics Powerhouse in PRinS3
In the modern era of computational drug discovery data is abundant but insights are priceless. The challenge is not gaining access to massive protein databases or millions of bioactive molecules but integrating them meaningfully and turning them into actionable discoveries.
This is where ChemIn, a flagship module within the PRinS3 software suite, proves to be a game changer. It connects curated molecular databases with advanced sequence-based searches, chemical similarity indices, and AI-driven expansion to help researchers navigate chemical space and uncover novel drug candidates with unprecedented efficiency.
ChemIn at a Glance
ChemIn is more than a molecular search tool; it functions as a true cheminformatics control center that unifies protein and chemical data into a single platform.
Integrated Databases in ChemIn
- ChEMBL: drug-like small molecules with detailed bioactivity data.
- UniProtKB-Swiss-Prot: manually curated protein knowledge-base.
- UniProtKB: comprehensive protein entries (curated + automatic).
- BindingDB: protein–small molecule interaction repository.
By integrating these resources, ChemIn offers direct and target-specific access to proteins and their associated compounds.
What Makes ChemIn Unique?
ChemIn stands out as a data-driven bridge between protein sequences and chemical structures, offering:
- Protein Sequence Search: Use BLASTp or FASTA to find compounds linked to homologous proteins, even when no UniProt ID is available.
- Chemical Structure Search: Query SMILES strings or upload molecular files to identify exact matches or similar analogues.
- Activity Insights: Retrieve experimental data such as IC₅₀, Kᵢ, inhibition values, alongside compound identifiers (ChEMBL ID, BindingDB ID).
- Drug-Likeness Filters: Explore compound properties (LogP, HBA/HBD, PSA, MW, rotatable bonds) to refine hits.
- Chemical Similarity Index: Assess structural relationships with Tanimoto coefficients and visualize clusters.
- AI-Powered Expansion: Move beyond known chemical space by generating novel analogs that preserve desirable profiles.
Molecular Properties & Visualization
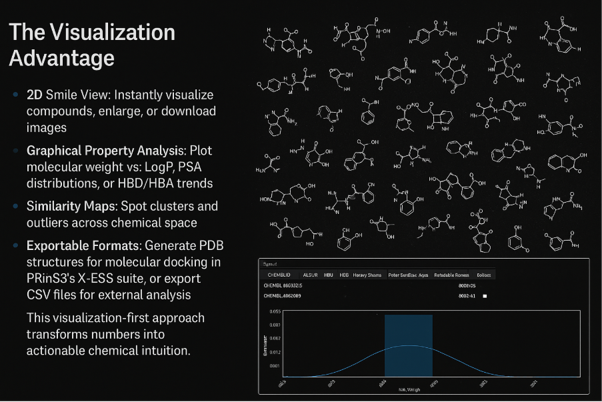
ChemIn isn’t just about raw data tables. It provides intuitive visualization tools to extract insights:
This visualization-first approach transforms numbers into actionable chemical intuition. Molecular descriptors such as LogP (lipophilicity), PSA (polar surface area), and HBD/HBA (hydrogen bond donors/acceptors) are fundamental indicators of drug-likeness, forming the basis of frameworks like Lipinski’s Rule of Five. By analysing and visualizing the distributions of these properties, researchers can quickly identify and filter out compounds that are unlikely to cross biological membranes or bind efficiently to their targets. This process not only streamlines compound selection but also enhances the probability of advancing molecules with favourable pharmacokinetic and binding characteristics.
Expanding Chemical Space with ChemIn
Chemical space is estimated to contain over 10⁶⁰ small organic molecules, yet only a small fraction is synthetically accessible or biologically relevant. To navigate this vast landscape, researchers rely on curated resources such as ChEMBL, PubChem, and BindingDB, which provide high-quality bioactivity data that help prioritize meaningful subsets of molecules. Within this context, the true strength of ChemIn lies in its ability to not only access these resources seamlessly but also to expand the explored chemical space by integrating diverse protein and compound data. This expansion enables the identification of novel scaffolds, unexplored bioactivities, and promising leads that might otherwise remain hidden in the immense chemical universe. With AI-assisted similarity searches, researchers can:
- Identify novel scaffolds beyond known chemical matter.
- Maintain drug-like property profiles while exploring chemical diversity.
- Reduce time spent on manual cross-referencing between multiple databases.
ChemIn is not just another cheminformatics utility — it is a comprehensive discovery platform that allows scientists to:
- Link protein sequences or drug smiles to chemical matter.
- Extract bioactivity insights with precision.
- Refine and visualize datasets with clarity.
- Seamlessly transition from data mining → compound analysis for docking studies.
In an age where AI and computational chemistry are reshaping pharmaceuticals, ChemIn is an indispensable partner for medicinal chemists, computational scientists, and structural biologists alike.
Complete details about these applications can be found on our official website at https://prescience.in/. To obtain access to the platform and obtain all the information required for the best possible experience, we respectfully ask that you contact us by email at support@prescience.in and obtain information at https://prescience.in/prins3/.